Our main product dashboard is written in Rails. This Rails application uses 74 keys, shared between 16 teams with part-ownership among themselves. A DevOps team has super ownership of all the keys.
Now, imagine that one of the 16 teams wants to change a key. They raise a ticket for the DevOps team. Then the DevOps team makes changes to the key and deploy it on all production machines. Furthermore, since we are SOC2 compliant, we also have to rotate all our keys every 90 days. This activity would take ~35 man-hours just for the Rails app.
In the summer of 2019, we decided it was time to re-architect the key management system of our Rails application.
The Vision
Suppose a team at BrowserStack comes up with a new component or a new service. That service could have some authentication keys or may use some third-party tools. After our planned re-architecting, the teams would be able to add their keys to a secure, central location where:
- their keys will not be visible to other teams.
- they can change their keys directly in the central system. The new keys will be dynamically loaded into their application.
- the keys can be rotated without involving other teams.
How were we managing our keys thus far?
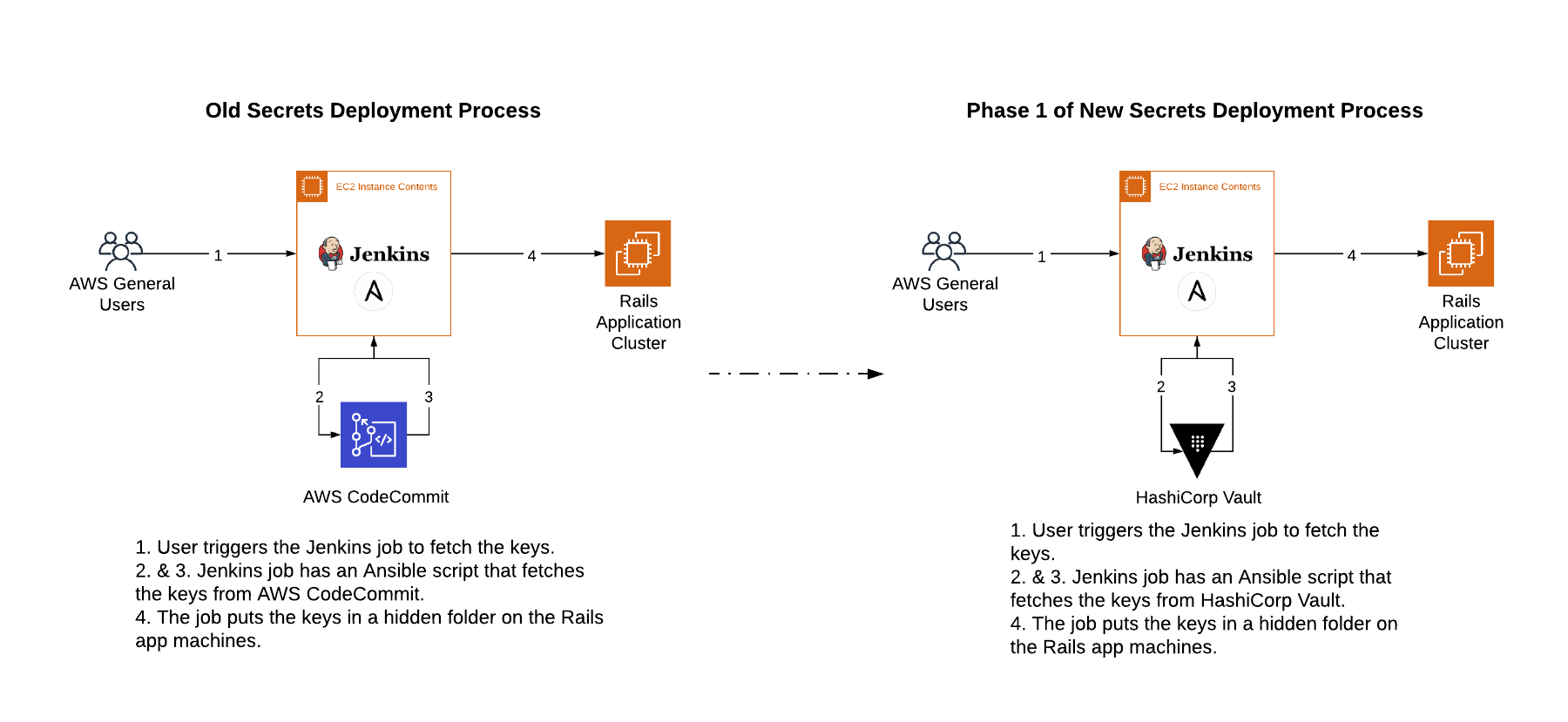
We stored our keys in an AWS CodeCommit repository, accessible only to the senior members of the DevOps team.
Whenever we needed to update them, we would start a Jenkins job. It would fetch the keys from CodeCommit and put them in a hidden folder on the production machines. Then we would start a deployment script to deploy the application. It would pick up the keys from the hidden folder and create a new release.
The problem with AWS CodeCommit
The keys were stored in a plaintext file. Access to that one file meant access to all the keys. There was no way of keeping a part of the file encrypted and the rest visible to teams.
We considered dividing the keys into team-owned YAML files. The Jenkins job would merge the file and deploy a single YAML file on the production machine. It was better than plaintext, but as far as secrets management goes, it was still clumsy.
Exploring the solutions: Knox vs Vault
A maxim we go by at BrowserStack is to not reinvent the wheel. Developing a secrets management component of our own was a low priority. We needed to find a suitable pre-existing solution instead.
A simple Google search for 'manage secrets' led us to HashiCorp Vault. We also find an alternative to Vault in Knox, an open-source key management solution maintained by Pinterest.
Here is the feature comparison that we did:
- Access management of the keys: Both Vault and Knox provide role-based policies.
- Versioning of the keys: Both Vault and Knox provide this.
- Consistency in staging and production environments: Vault has built-in support for Ansible. Knox doesn't.
- Library Support for dynamic retrieval of secrets and configurations: Vault supports Ruby, Python, and Java. Knox only has Rest API support, which means we would have to create libraries on our own.
- Uptime: Vault + Backend Storage architecture provides HA and is fault-tolerant out of the box. For Knox, we would have to find a workaround to get HA.
- Documentation: HashiCorp maintains extensive documentation for Vault. Knox fell short here.
- Cost Comparison: The number of hosted machines we would need for either Vault or Knox was the same, so the cost was comparable.
In the end, we chose Vault.
Vault, who’s got your back?
Vault as a component has backend storage. But the filesystem does not allow us to scale since every Vault will have its own storage. For the Vault system to be HA, there should be at least one more Vault server to serve as backup if any one system were to go down.
But here is the issue: if we don't use a backend storage, we will have to create a service that will sync the two Vaults from time to time. Since there are solutions that can provide this functionality, we looked at two backend storage solutions for Vault: Consul and DynamoDB.
We compared the two on the following criteria:
- Features/Implementation ideas:
DynamoDB is a NoSQL database provided by AWS. Consul is open-source.
Both of them have integrations with Vault.
With DynamoDB, there'll be no cost of additional machines. It has cloud storage, and the two Vault servers would be enough. With Consul however, we would need a 2-3 architecture to make the system HA, i.e., we'll need two Vault servers and three Consul servers. - Cost calculations:
For DynamoDB, the cost depends on the number of reads and writes per month.
Cost per machine per month: $70.08 (On-Demand) or $45.53 (Reserved)
Cost for two Vault servers (V) = $45.53 * 2 = $91.06
So for 2 million reads and 1 million writes per month, AWS DynamoDB will cost us around $4.
For Consul:
Cost per machine per month: $70.08 (On-Demand) or $45.53 (Reserved)
Assuming we go ahead with Reserved,
Cost for two Vault servers (V) = $45.53 * 2 = $91.06
Cost for three Vault server (C) = $45.53 * 3 = $136.59
Total Cost = V + C = $227.65
[Note: These calculations are based on AWS pricing in Summer '19.] - Uptime: DynamoDB is managed by AWS. We'll manage Consul ourselves at BrowserStack.
There were similarities too. Both Consul and DynamoDB are HA, easy to maintain and offer plenty of useful integrations.
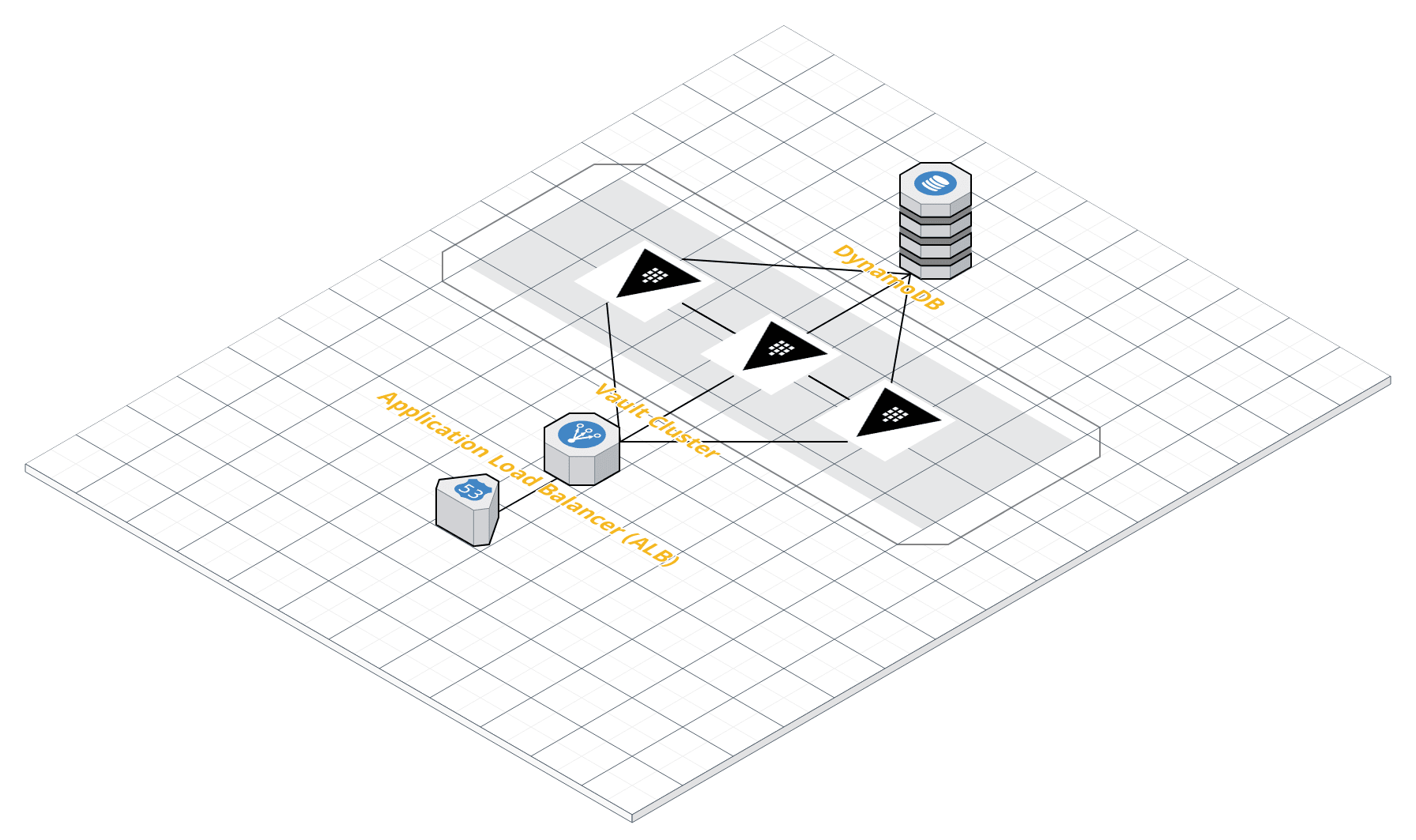
In the end, it came down to cost and we picked DynamoDB. One week later, our revamped deployment architecture looked like this:
Deploying Vault
The Vault deployment was iterative. In the first phase, we were testing the waters. We wanted to see if Vault could (significantly) reduce the hours we spent on our key rotation activity.
There were two Vault features we had our eyes on:
- Role-based access: Every key stored in the Vault is a path and you can access roles to that path for a user. Here, the user entity can mean a person or a service.
- SSO with AWS and GitHub: Explicitly mentioning AWS since our machines are also considered as users to Vault.
This is what our Vault architecture looked like:
Why did we use Ansible to deploy the keys?
We kept Ansible as a way to interact with Vault for two reasons.
First was to minimize risk. Introducing a new service around the management of secrets can produce some scary unknowns. What if my Vault becomes unresponsive (due to network failure) at the time of fetching the keys? We would need a system to implement a cache.
Secondly, we didn't want to spend more of our time maintaining the uptime of Vault as a service. At BrowserStack, we use Ansible for our infrastructure management. Since most of our developers were familiar with Ansible, keeping it around made things easier.
- We changed our deploys to make use of templated YAML files. An Ansible plugin fetches the secrets from the Vault, populates the template with them, and places the template in a location that applications can access. These templates can be committed in the application repositories and shared with developers so they can better understand the structure of the YAML file.
- We can re-use the template in staging just by populating them with staging values. Templating also allows us to use derived values in our YAML and order the keys. We also patched the Vault plugin to cache the values in-memory.
How does secret management with Vault work?
Once set up, integrating Vault was simple. Vault has a portal for accessing keys. It shows all the keys that we have access to, as well as values of their older versions.
For our setup, we created a key-value pair (KV2 in Vault terminology) mount point for pre-prod and a matching one for prod. Team leads and managers have access to their respective teams' keys in pre-prod mount point, with permissions to access/view/change them.
Every 5 mins, a cron job does a sweep for any mismatching keys in pre-prod and prod mount points. If it finds that a mismatch (implying that a key was updated in pre-prod mount point), an email notification is sent to the 'owner' of those keys, telling them that the key needs to be deployed on production system.
The notification email has 'deploy' and 'revert' links that take the recipient (team-owner) to a CI/CD pipeline. Once they hit 'deploy', it merges the updated key in a prod mount point and deploys the application in question.
If an updated key in pre-prod mount is not deployed within 6 hours, the changes are reverted.
Why did we have different mount points for pre-prod and prod?
There were several reasons:
- We wanted a clear versioning history of every key in BrowserStack.
- We wanted a separate stage where we could review/merge/revert keys. It'd also allow team leads and managers to simulate a dry run and see what they'd be deploying.
- Using a separate mount point (accessible only by automation) allowed us to be sure that whichever keys are present in the pre-prod mount point will be validated and verified by the automation before being deployed on production.
- The feature is provided out of the box by the Vault (and the wheel need not be reinvented).
How does the automation know where to deploy the key?
- We have a central Ansible repo where we store all our playbooks, roles and inventory.
- To deploy a key end-to-end, we just need to know which playbook and which tag to run.
- We have stored these two as secret metadata in the KV2 store and Voila! The secrets can be deployed end-to-end, without any external (aka manual) intervention.
How do instances and BrowserStack employees access the Vault?
Access control is everything. For Vault, we classified access requesters into 3 types: individuals, AWS EC2 instances, and non-AWS EC2 instances.
- For individuals, we use a simple GitHub auth backend with a full-fledged cubbyhole mount point. This auth backend also makes sure that the individual is a part of the BrowserStack organization on GitHub.
- AWS EC2 instances use the AWS auth backend with the EC2 auth method. The Jenkins container uses this method to fetch the keys (as shown in Fig. 1).
- For non-EC2 instances, we have Ansible roles deploying different pem files for each host group on the target instances. The instances can then fetch a temporary token with the help of this pem file using the TLS Certificates Auth method.
All auth backends allow a max TTL of 30 mins for the authentication tokens. Along with this, we have disabled the use of root token anywhere within BrowserStack.
So close, yet so far
Within one week, we had set up and deployed a secrets management system for our Rails app using Vault and DynamoDB.
Engineers can see and modify their keys without involving DevOps. Phew!
Our 'quarterly' key rotation activity used to take us 30-35 man-hours, per rotation, for the Rails app alone. After Phase 1 of Vault deployment, it takes ~12 hours. Progress!
Now, the vision we set out with is yet to be realized. But with Phase 1, we have figured out the direction and laid down the groundwork for improvements over time, which will involve:
- Removing the dependency of a single YAML file consisting of all the keys for the application. Instead, we want to call Vault within the application itself using the python/ruby/nodejs libraries. This will remove the dependency of having to deploy the application after every key rotation. The AWS instance of the application will have a role attached that will grant access to the Vault. Now that we know (for sure) that Vault works with our existing system, this is a must-have.
- Moving other systems to Vault. We do have a bunch of cool applications, besides the Rails app.
- Building systems around Vault to handle our org-wide key rotation, every 90-days, automatically.
Our secrets management overhaul is not a sprint but a marathon. And we believe that moving in the right direction at the right pace is what truly matters.