
Here at BrowserStack, our engineers run on passion and coffee to build and ship awesome features at an incredible frequency to show our commitment to our loyal users worldwide. Here, our teams have to maintain confidence that their code works as intended, and indeed, our methodology is not based on “Hope that everything works”.
We help organizations, irrespective of their size, to deliver. To be able to do that, we have to be very critical about our delivery first. At the rate we push the code, doing anything manually will only hinder our engineer’s ability.
“It is beneath the dignity of excellent men to waste their time in the calculation when any peasant could do the work just as accurately with the aid of a machine”
- Gottfried Leibniz, 1694
We took that seriously. We don’t want to disrespect our engineers. So, we made sure none of our engineers will work on repetitive and menial tasks ever again, and a good CI/CD pipeline ensures just that. From testing out the code in different fashions to the final deployment, a well-designed CI/CD can help drastically reduce the time taken in each step and increase free time for our engineers to have fun.
Initially, when our teams were small, for CI/CD, we had multiple platforms for deployments based on use-cases.
We had a single m5.xlarge machine on AWS running Jenkins in a Docker container. The jobs were set up manually from the Jenkins UI. Another tool we use was Samson which was again set up on a standalone machine mostly used for application deploys. Apart from this, several other teams had set up their own Jenkins to cater to their needs.
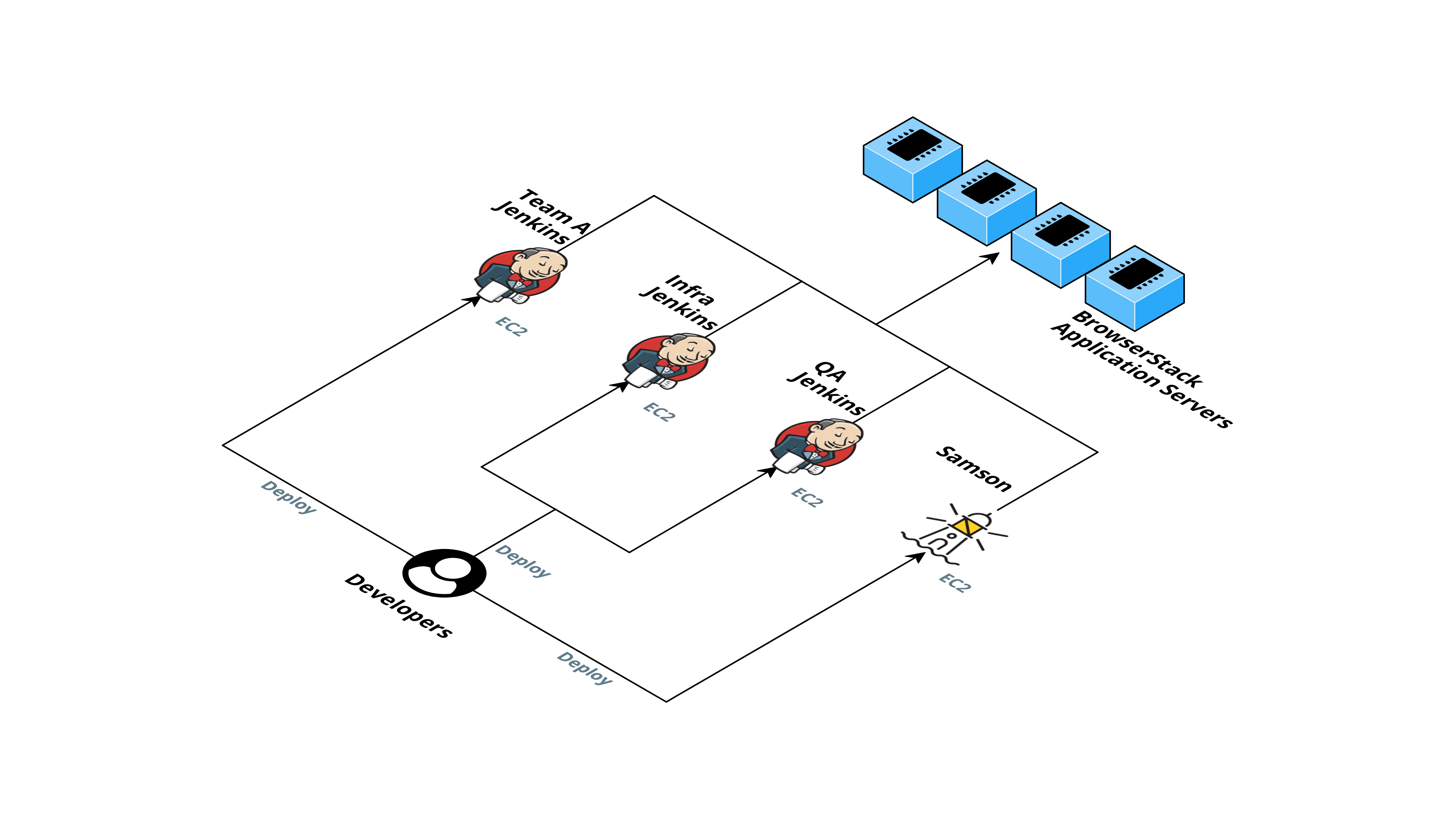

This used to work pretty well until a few months ago. As the company started to “Blitzscale”, the number of engineers in the team almost doubled, and so did the number of jobs run on these platforms.
We didn’t over-engineer our CI/CD processes to handle the scalability in the past. Informally speaking, in a scalable system, things should not get incrementally worse as we move from small to large. And there is only so much we can scale vertically. Vertical scaling will cost more, and even if cost-saving is not a priority, technology and equipment are still obviously limited by its time. So, it was time for us to scale horizontally.
A good scalable system has:
- Size scalability: Adding more nodes should make the system linearly faster
- Administrative scalability: Adding more nodes should not increase the administrative costs
- Storage scalability: Adding more nodes should not increase the probability of data loss
- Availability: Adding more nodes should increase the availability of the system
The issue with our setup was:
- The distributed nature of deploys used to create many issues in access management, tracking deploys, and an added overhead of maintenance of all these platforms.
- Scalability was an issue as the resource requirement was going up, and these platforms were just being run on a single machine.
- Single point of failure
- Reproducibility - If the machine volume ever got corrupted, there was no way to recover the jobs and pipelines as they were set up manually and not maintained anywhere.
More or less, it was becoming cumbersome to manage it manually through UI, and also, our anxiety was going through the roof due to the issues mentioned above.
Major decisions
We wanted to engineer a distributed system for CI/CD to solve issues like scalability, single point of failure, maintenance, and growing team size.
In the past, we were aware of all the issues we were going to encounter, so to make the transition easier, we decided to set up Jenkins to run in a Docker container the past.
To automate scaling, deployment, and management of containers more efficiently, we have gone for Kubernetes. Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. Instead of self-managed service, we have opted for managed service called AWS EKS - Elastic Kubernetes Service to further streamline the process. We plan on describing our AWS adventures further in a separate post.
Our entire stack already runs on AWS. So, choosing AWS EKS will ensure that all our services will work in tandem with low latency.
One more crucial decision to solve the growing team size is shifting configuring systems from UI to code. Shifting to Infrastructure as Code and Configuration as Code further streamlined our CI/CD process.
Managing Jobs as Code
When making Jenkins Infra as Code, its jobs should be deployed from code instead of creating jobs on Jenkins manually.
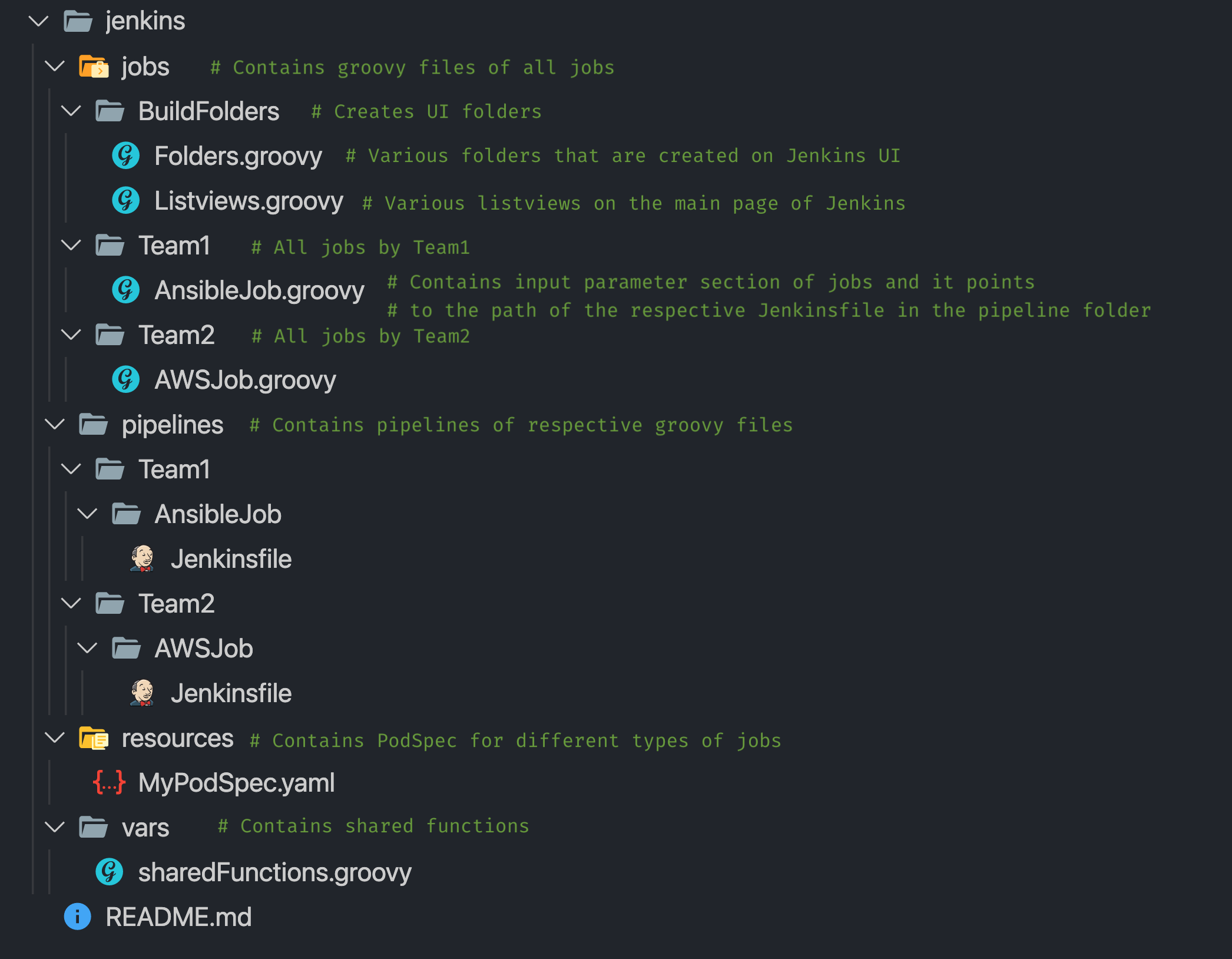
We have a Job Generator that reads groovy files and Jenkinsfile from our GitHub repo for easy management of jobs and creates these jobs on Jenkins.
The advantage of this is:
- The files can be committed to git, just like code
- The audit becomes easy
- Bugs can be tracked and fixed
- Granting and revoking permissions for an individual is an edit away. More on this in “Access Management for Jobs” below.
So any new job committed in the repo will be added to Jenkins, and any manual modification of jobs on Jenkins UI will be reverted to the original configuration. This also enables us to manage job structure in folders/list views for ease of use.
Github repository structure:
Access Management for jobs
It is always advised to follow the “Principle of Least Privilege”, i.e., giving a person only essential privileges to perform their intended function. And Jenkins has ‘manage and assign role’ for providing access to different jobs to different individuals.
It's a matrix-like structure that becomes very difficult to manage from UI when roles and people grow in size. There is a high probability of giving wrong permissions to the wrong person.
This is how it’s looking in our “Blitzscale” phase:

We use Jenkins CasC (Configuration as Code) plugin to deploy configuration on Jenkins. So accesses of each job are mapped to individuals in a YAML file while deploying. This mapping is templated in the helm values file in the form of permissions and the user matrix, which specifies all the permissions and maps these permissions to users. This matrix is translated to Jenkins permissions by the helm.
Sample template:
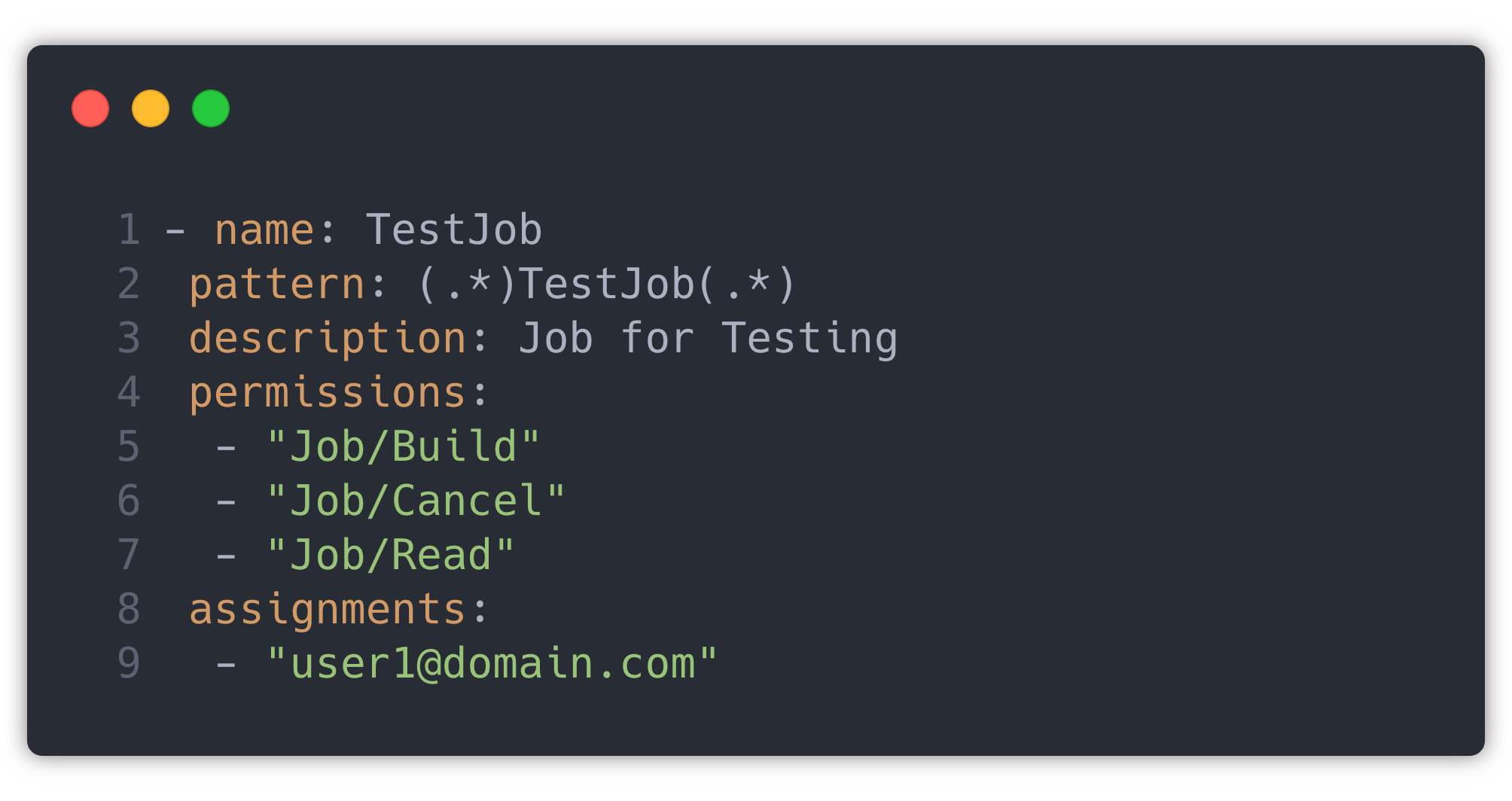
This is translated into the ✅ in the corresponding check box in the above image, which Jenkins uses.
The data for populating this user matrix is fetched from an API exposed to the internal tool we have built for access management. This tool handles the complete lifecycle of a request, from creating a request to approving and revoking access. The JSON data returned by this API is templated into a generic template by ansible, which creates the “Configuration as Code” file for Jenkins. More about this is mentioned in the “Jenkins Deployment via Ansible” section below.
Shared Library functions
The idea of managing all the Jenkins jobs as code to make the system reproducible wasn’t much of a complex problem to solve as this idea had been floating over the internet for a while.
Maintenance of the code was something we were concerned with. Almost all of the jobs had a few generic components like authentication with various components like AWS, Hashicorp Vault, sending notifications, fetching relevant keys/information from secrets, etc.
Managing these steps separately for every job would have added overhead of maintenance effort as any change would have to be made for all jobs. This issue was solved by using a list of shared functions committed in the repository as a separate file, and these functions are called in job pipelines.
The shared functions are imported using the following line in pipeline:
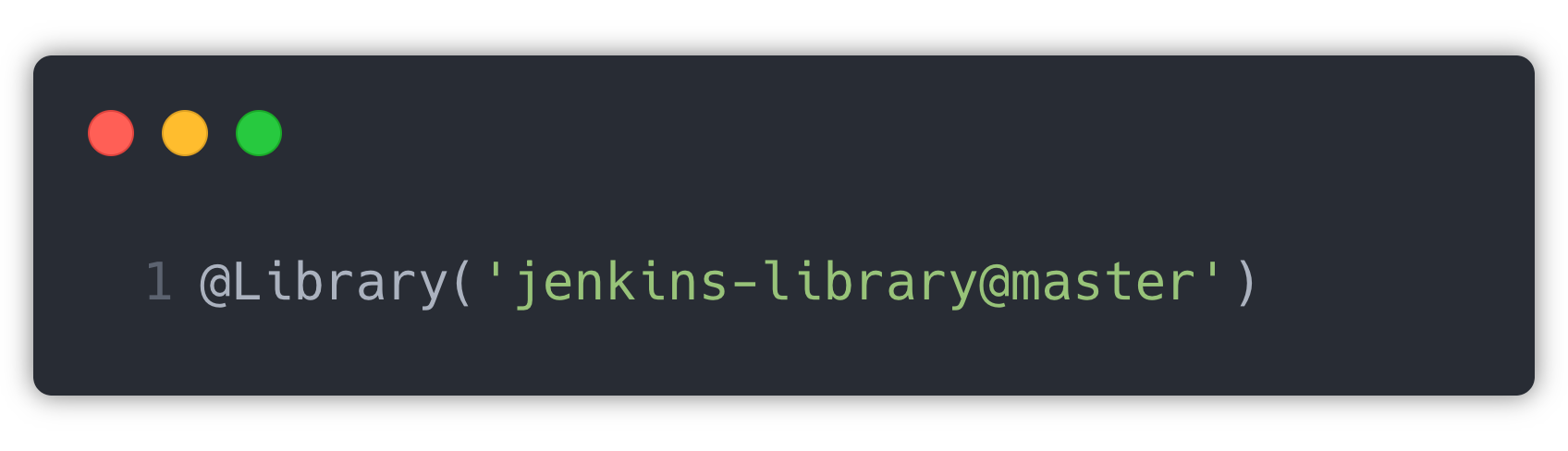
Here, ‘master’ is the branch from which the files need to be picked. These shared function files are maintained inside the “vars” folder in the repository.
Different PodSpecs for different types of jobs
Every pipeline Job has a PodSpec that decides which Node the Job will run, different secrets, and AWS resources that the job can access.
PodSpec yaml looks like:
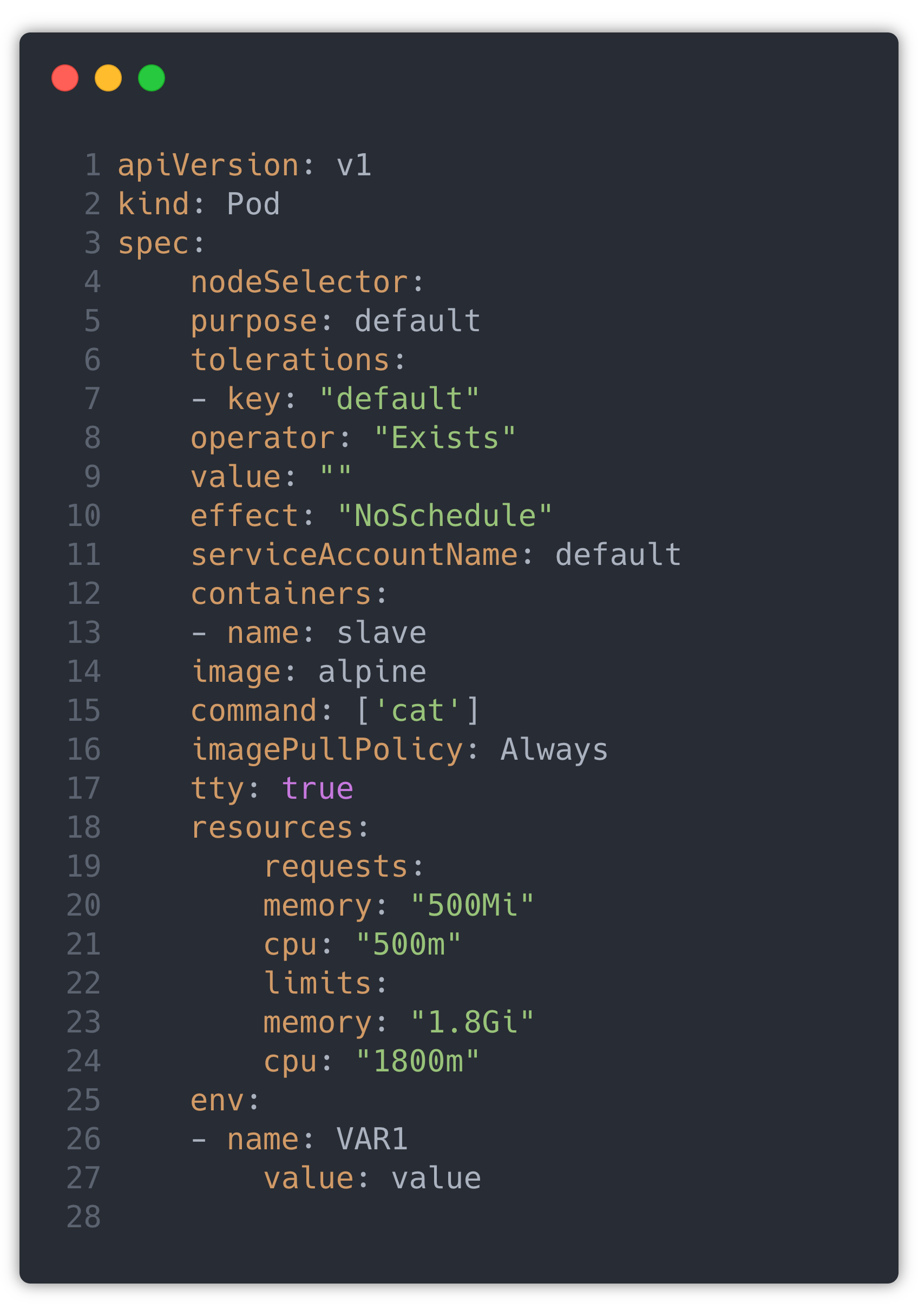
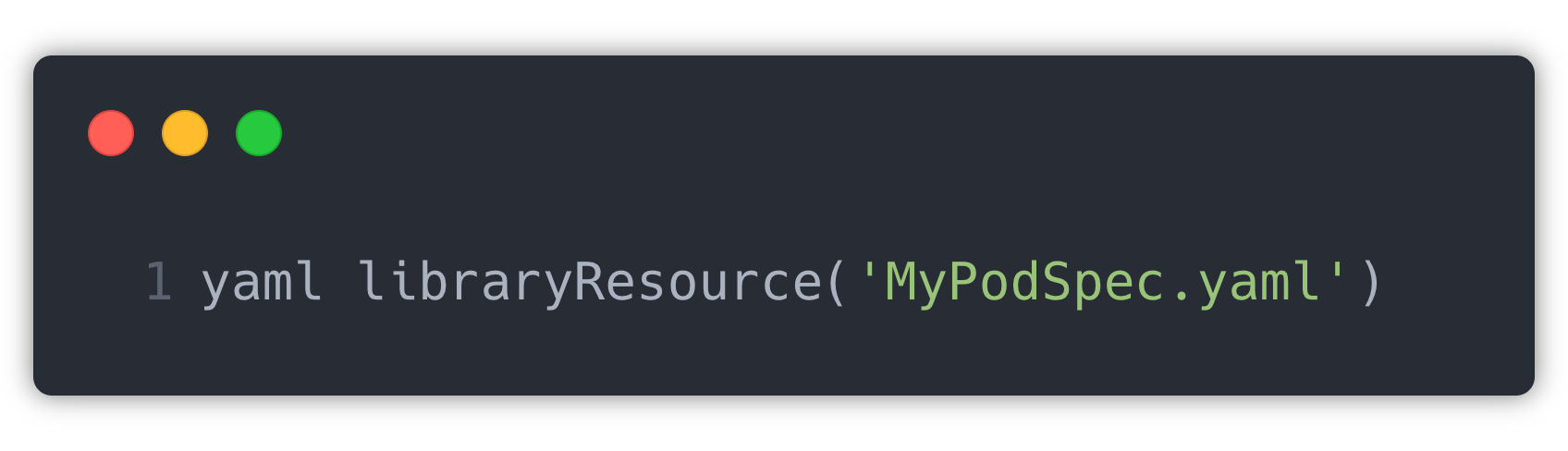
This PodSpec part gets repeated in all jobs with minor changes. So instead of repeating the whole Pod Spec in the agent section in Jenkins file, we have created a different Pod Spec YAML and placed it in a shared library.
They are imported in Jenkins file as:
Different jobs have different requirements like packages that need to be installed in the container, access requirements like AWS services, secrets, ssh and deploy permissions, etc.
PodSpec used in Jenkins file has the following major configurations:
- Docker Image - container is created using this image. These predefined images have all the required packages installed
- Service Account - This specifies the Kubernetes service account, which will be associated with the pod. Most of the accesses like AWS access, fetching secrets, etc., have been linked to these service accounts.
- Node Selector - We have defined different kinds of nodes based on the types of tasks they need to run. SSH access to different components is defined separately for different node groups.
Example: For a Jenkins job that runs Ansible, the container that comes up needs to have Ansible installed
So we have different docker images for different types of jobs.
Using Helm
Helm is a tool that makes maintenance and deployment of Kubernetes applications easy. All the configuration is maintained in the form of charts. Charts make maintenance and versioning of configuration easy. We use the Jenkins Helm Chart as the base and overwrite all the custom configurations like secrets, permissions matrix, environment variables, etc. All the Kubernetes configurations like namespace, nodeSelector, resources, docker images, etc., are also maintained in the same file. This file used for overwriting default values is templated via ansible during the deployment.
Jenkins Deployment via Ansible
Jenkins is used for deployments on servers. So to set up Jenkins itself, we need automation as well. Even though helm charts have made the deployment process easy, Jenkins deployment in our setup required a couple of more steps-
- Checking the cluster as we use different clusters for production and staging.
- Fetching some keys required for Jenkins plugins like slackNotification, git, etc.
- Fetching the user permissions from an API exposed on our internal tool.
- Templating the secrets and user matrix to generate a helm file and running the deployment.
- Creating 2 ingress controllers for internal and external traffic.
To make this process even simpler, we used Ansible, which makes all the checks on the existing Kubernetes cluster and deploys changes to Jenkins or brings up Jenkins from scratch if it does not exist. This deployment also adds Job Generator to Jenkins as a Starting point. This allowed us to deploy changes to Jenkins with a single command. We have Kubernetes CronJob that runs twice a day which updates the access matrix for adding new accesses. It gets an access matrix from an internal access management tool and secrets from the vault to do a deployment.
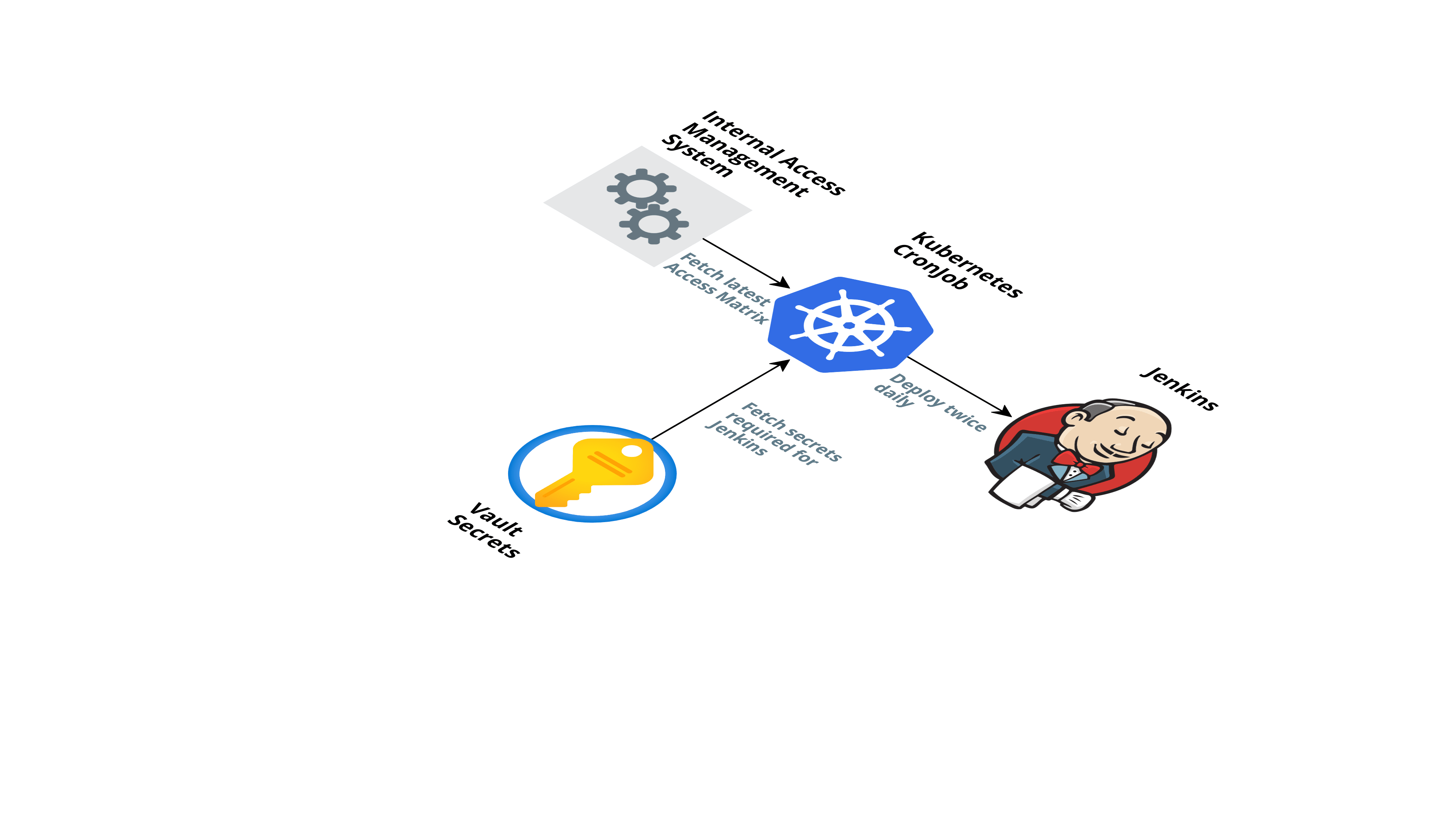
Jenkins and plugins Upgrade
When using any system, it is necessary to upgrade it from time to time. For Jenkins deployment using Kubernetes, it takes just a few minutes to bring up a new Jenkins Pod and start using it.
We create a new Jenkins Image with new Jenkins image/ plugin versions for the upgrade process, test the image by deploying it on staging Jenkins, and then deploy it to production.
If anything goes wrong with this new upgrade, we can always revert the deployment using the older image in the "Configuration as a Code" file.
Notification System
Jenkins has a wide range of options for sending notifications. We use slack internally in the company, so we decided to stick with that for job notifications. We use notification for Job completion alerts to deployers. Jenkins already had an easy-to-configure plugin for slack notifications, which allowed sending notifications to any user/channel. We wrote a function on top of this plugin to send a customized notification as needed by us.
Making Jenkins Private and remote triggers
Considering the security aspects, we wanted Jenkins to be only accessible internally using VPN. This was achieved using an internal load balancer which allowed traffic only from private IPs in the network.
To fully utilize the capabilities of a CI/CD system, we also wanted to integrate the system with GitHub PR checks and remote triggers. The private load balancer did not allow for this directly. This problem was solved using two different ingress controllers, one for internal traffic and open to all routes and a second one for remote triggers open to only specific jobs and routes. The reverse proxy setup allowed GitHub to trigger jobs remotely while not compromising the system's security.
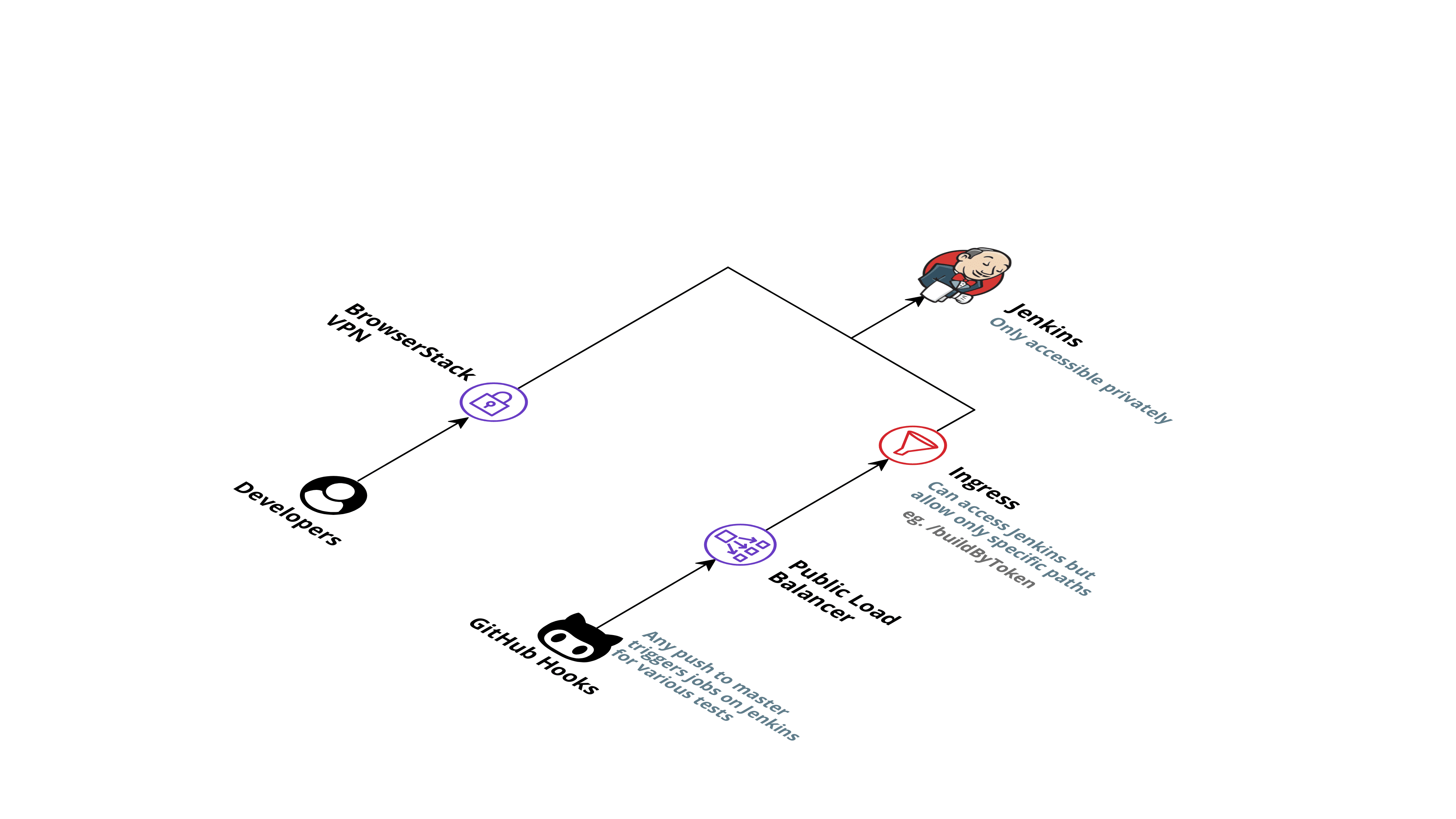
The final result
This is how our final architecture looks like at the end of our journey:
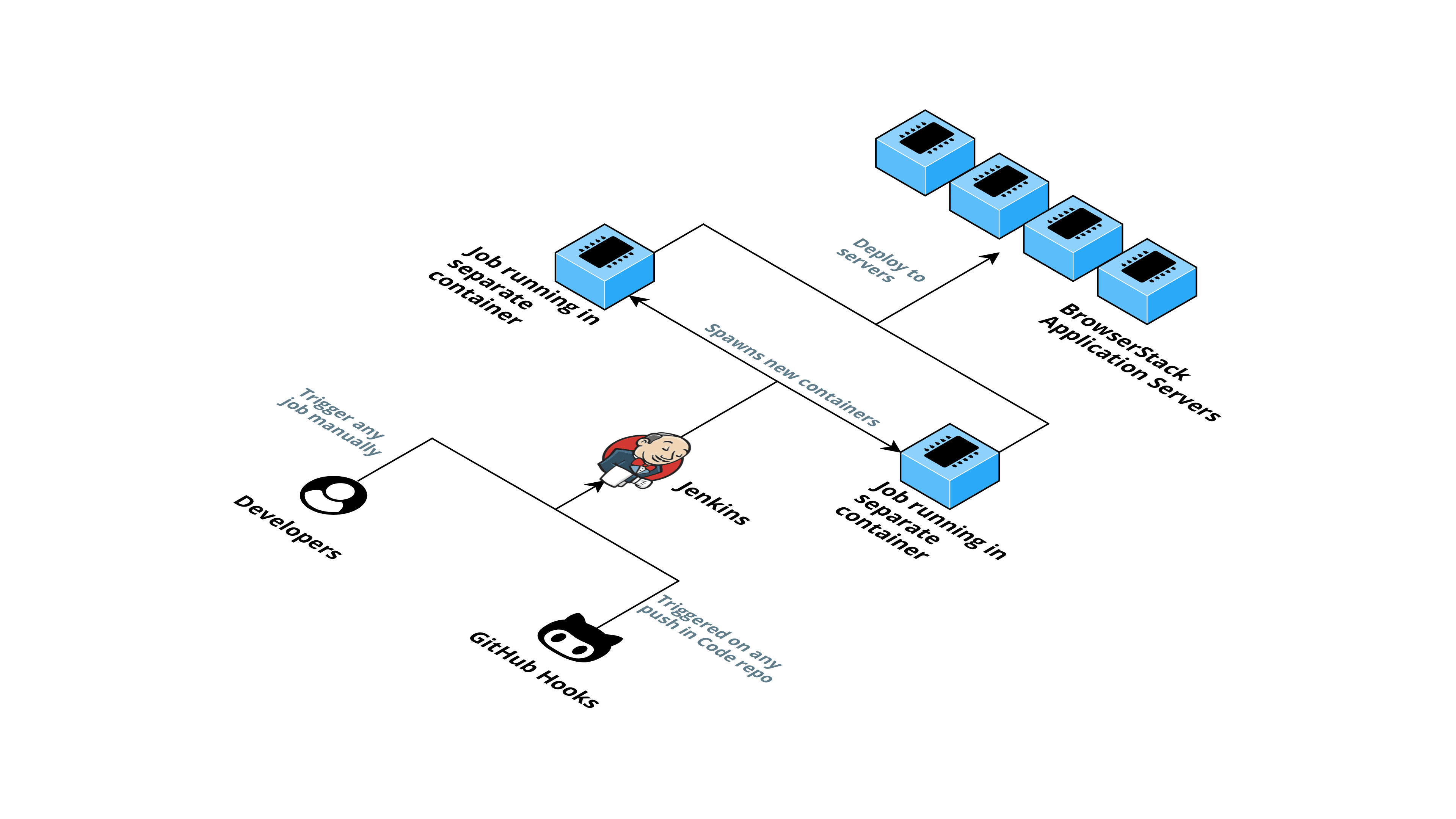
At high-level, we have a highly scalable Jenkins setup and a centralized configuration to manage.
To show what we mean by the above statement, take a look at our old and new architecture:
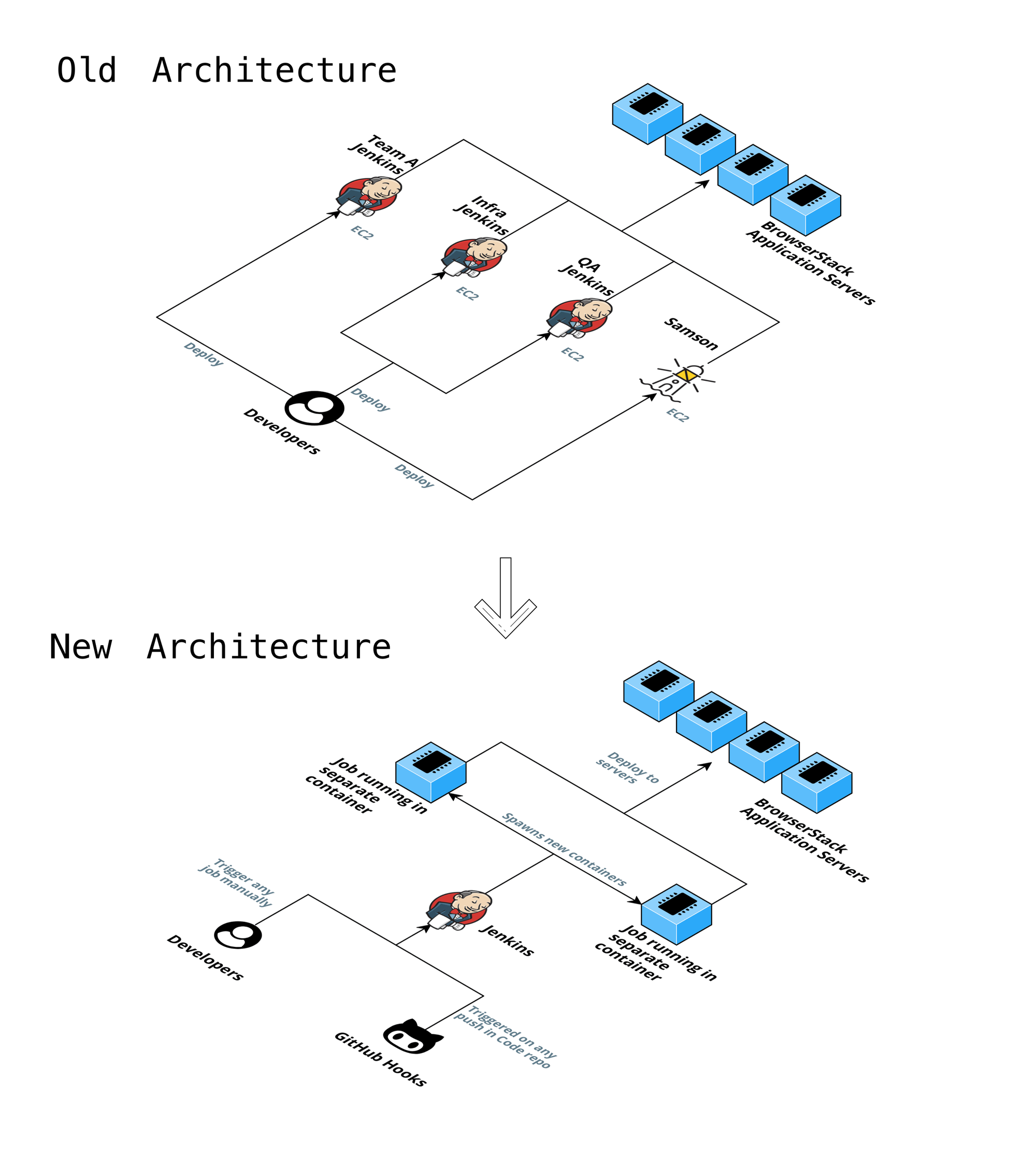
In the old architecture, we have multiple Jenkins to manage, from infrastructure to its configuration. When the administrative work is spread across individual developers and teams like this, it is nothing but a disaster waiting to happen.
But now, we have completely shifted managing Jenkins’ configuration to GitHub and infrastructure to AWS EKS.
Is it worth the effort we have put?
Absolutely! Let’s look at the improvements we have made with this refactor:
- No production deploys from local machines. For any deployment, developers can create a job easily by pushing the job pipeline in the code repo.
- Jobs' waiting time has come down as when Jobs are triggered, new AWS instances are booted(if all resources are busy) to run the job and terminated after done.
- When the Jobs are not running, all the Jenkins salves are scaled-down, so it saves a lot of AWS resources compared to previous setups where Jenkins slaves were UP at all times.
- Developers have only build access to jobs, and any modifications in Job is done through PR reviews.
- Very low maintenance of Jenkins because if Jenkins Container goes down, it is automatically brought back up by Kubernetes.
- Upgrading Jenkins has become easy.
- It took four months to build this system and migrating existing jobs from different deployment systems.
Closing thoughts
Is it a panacea for our CI/CD issues? Honestly, no one can say that in software industry with certainty. But software engineering is all about context, use case, and trade-offs, or more famously, “It depends”. No matter how advanced the systems are, there is always a flaw or a need for refactoring that arises in the future due to many reasons like improvement in the technology, increase in user base, organisation expansion, etc.
But did our engineers do their best to address the issue and create a solution that would last for substantial years to come? Absolutely!