
Why integration tests?
Love it or hate it; testing is a vital part of any software development cycle. Since it would be highly undesirable for buggy code to be deployed to the millions of devices accessing Twitter, Twitter.com has thousands of unit tests and nearly a hundred integration tests.
Integration tests, also known as smoke tests, allow us to automatically verify that web features are functioning properly across a variety of platforms and browsers. Automated smoke tests are great, because they allow us to verify crucial functionalities without having an army of QA engineers doing the same thing over and over again.
In terms of the technical implementation, we use the Webdriver framework with Selenium tests written in JavaScript and have developed an infrastructure that allows us to run individual test across the full suite locally, as well as outsource to remote environments. BrowserStack provides us with the ability to run our tests across a variety of real devices, browsers and operating systems at scale.
In terms of frequency, we run smoke tests across multiple build configurations—with every remote branch update before merging, after a branch has been merged into master and hourly on the master branch (aka “auto-smoke” job) before global deploy. If any of the smoke tests consistently fail at any of the stages, we disallow merging until all the tests pass. We treat the test results extremely seriously because none of the tests could or should fail, since it prevents deployment of new code until we are able to fix whatever is causing the failure.
This brings a number of challenges to web infrastructure engineers—while still faster than human actions, Selenium tests are slow compared to smaller programmatic Jest tests. A test that is conducted over a network, with several moving pieces, each dependent on the other, might sometimes fail unexpectedly due to a random network, application, or platform failure. It gets even more challenging when we don’t have control over the underlying hardware on which the tests are run. We have run into challenges with flakiness—a few tests (out of hundreds) intermittently failing without signaling an actual failure with our software.
This flakiness led to a loss of confidence in the test results. Developers would frequently ignore smoke test failures and merge their code to master, only to recognize later that the supposedly flaky test was signaling an actual issue. Finding the root cause, reverting, having a post-mortem—these are time consuming and also a little stressful. It is possible to set a config for retrying the test on a unit level, but what happens if the device you are starting to run your test on lost its connection to the Internet, or the browser won’t open?
A potential solution is to do a full test build restart. However, that is not practical, since those builds take a long time to complete. Another solution would be for the developer to manually supervise the offending test. For example, the test runs are screenshotted, so it is possible to rewatch the recording of the test, or run it locally. But that still results in drop in confidence in the test results and a waste of expensive engineer time.
We are going to talk about ways we’ve mitigated the challenges related to testing, primarily through implementing the use of device-level retries. We have also developed a visual tool, a heatmap graph of successful tests, called the Test Dashboard, to display success/failure rates over time.
The Stack
The core of our testing infrastructure is the ability to run Selenium Webdriver tests via a tunnel established with BrowserStack. BrowserStack is a platform that allows us to test twitter.com across browsers, operating systems, and real mobile devices. Here is a graph depicting the information flow.
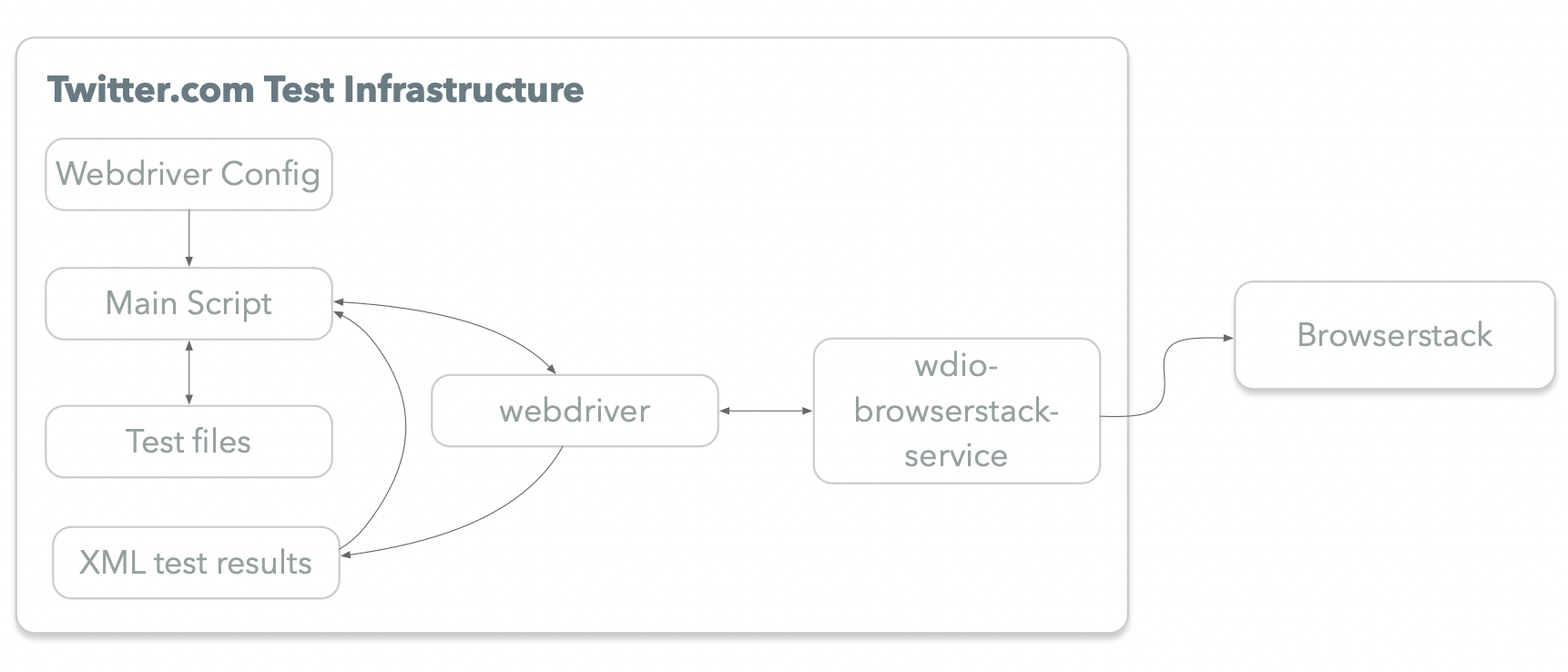
- Webdriver.io allows us to specify configurations for our JavaScript Selenium tests.
- Wdio-browserstack-service is an open-source package developed by one of our engineers; it allows us to transmit data to/from Browserstack.
- Junit Reporter Webdriver plug-in helps with saving the test result data in XML format.
We can pick and choose which devices to test the website on with Browserstack. After tests are run, the results are sent back and stored as XML files. We then read them in and convert to JSON objects, which allows us to do further custom processing.
The solution(s)
Adding support for device-level retries resolved our long-lived pain caused by test flakiness. We programmatically check for failures by reading in XML files and rerun the test case that failed specifically again, versus the whole suite.
Before automatic device level retries, an average build success rate for pre-master branches over a two week period would be around 75%. After, we consistently see >90% success rate. Since the retries are also automated, the developer does not have to restart the build manually, neither would they have to wait for the entire test suite to run again. We are only retrying the tests that failed the first time.
Having support for processing the test results also allows us to display them visually. For example, below you will find a screenshot of our Smokes Dashboard. We use this dashboard to see how our integration tests performed on a unit basis over time, and whether they failed or not.
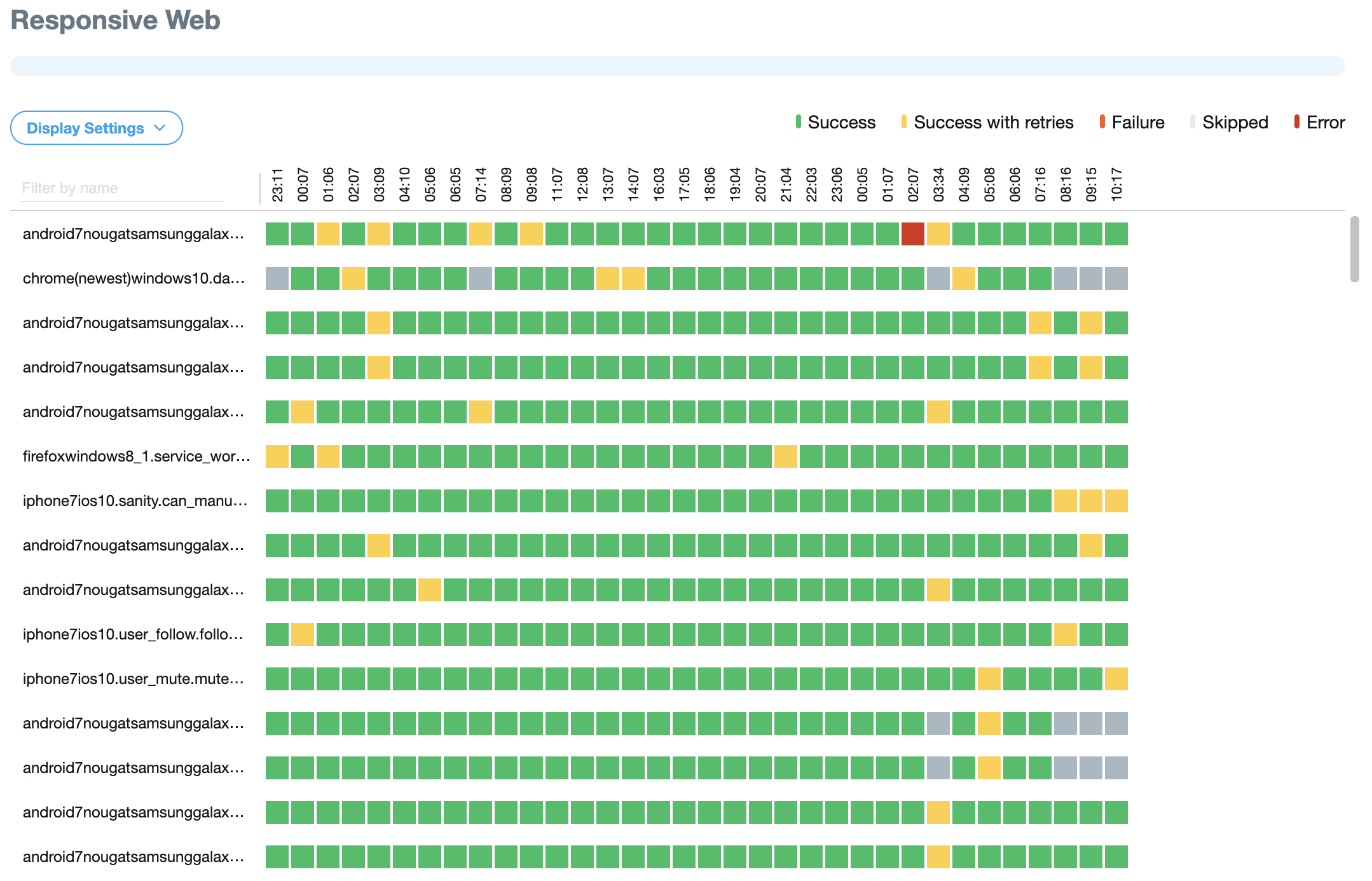
The yellow squares represent retried tests, tests that would’ve otherwise failed before rerunning them on a different device.
Developing a robust testing infrastructure is a slow process. There are a lot of moving pieces and integrations to be considered in order for it to be actually helpful. But once that’s done, developers can focus on things they actually enjoy doing, which is writing new code, instead of making sure the tests pass.
This blog post is written by Anna Goncharova and was originally published here.