Breakpoint 2026 opened on 12 May 2026 with an argument the QA community has been building toward for years: the speed-versus-quality trade-off in software testing is no longer a real constraint. Across the first day's keynotes, product launches, and fireside chats, engineering leaders from NVIDIA, Mastercard, Teladoc Health, Microsoft, Motorola Solutions, and Genpact made the same case from different angles, when AI handles execution, human judgment becomes the work, not the obstacle to it.

Quality or Speed: Why You No Longer Have to Choose
For years, the practical choice was: ship fast and accept the risk, or slow down and hold the standard. This keynote argues that AI-native quality engineering makes that choice obsolete. When AI handles test execution, engineering teams stay focused on judgment rather than throughput.
The End of Code as IP: Redefining Competitive Moats in the AI Era

With AI generating code from specs, the code itself is no longer your primary competitive moat. What cannot be replicated are your specs, your PRDs, and your test suites — they encode domain knowledge and product understanding that models cannot infer. Watch this if you want to rethink where engineering value actually sits in an AI-driven org.
The Pioneer's Playbook: Non-Determinism and the AI-Native QA Era

Jason Huggins separates what is genuinely changing in AI-era testing from what is hype. He focuses specifically on where AI is producing real, observable change in API, performance, and security testing, and directly challenges the decade-old shift-left mantra. Worth watching for any team that wants ground-level clarity rather than vendor talking points.
Building an AI-Native Quality Operating System: From Manual QA to Intelligent Quality Engineering

Mary Jinugu walked through what it actually looks like to replace a traditional QA model rather than layer AI on top of it. Her team moved to Copilot-driven automation, intent-based workflows, and agentic QA systems. Watch it for a step-by-step account of what changes, what breaks, and what you have to rebuild.
Testing AI Agents: From Confident Answers to Trustable Outcomes

AI agents fail in ways that look completely fine until they don't. Deepshikha and Anamika introduced a three-layer framework for testing agents across reasoning, actions, and end-to-end outcomes, covering prompt injection, data leakage, and how to set quality gates for systems without deterministic outputs. Watch it if you are testing or planning to deploy AI agents in production.
Scaling Your QA Career: From Individual Contributor to VP
Richard Hand's trajectory from individual contributor to Assistant VP gave this session a practical spine. He talked about what career growth in QA actually requires beyond technical skill: influencing cross-functional teams, tying testing decisions to business outcomes, and why senior leaders sometimes create the exact problems they ask QA to solve. Honest, specific, and useful at any career stage.
Guarding the Brand: Leveraging AI to Catch 'Invisible' UI Regressions at Scale
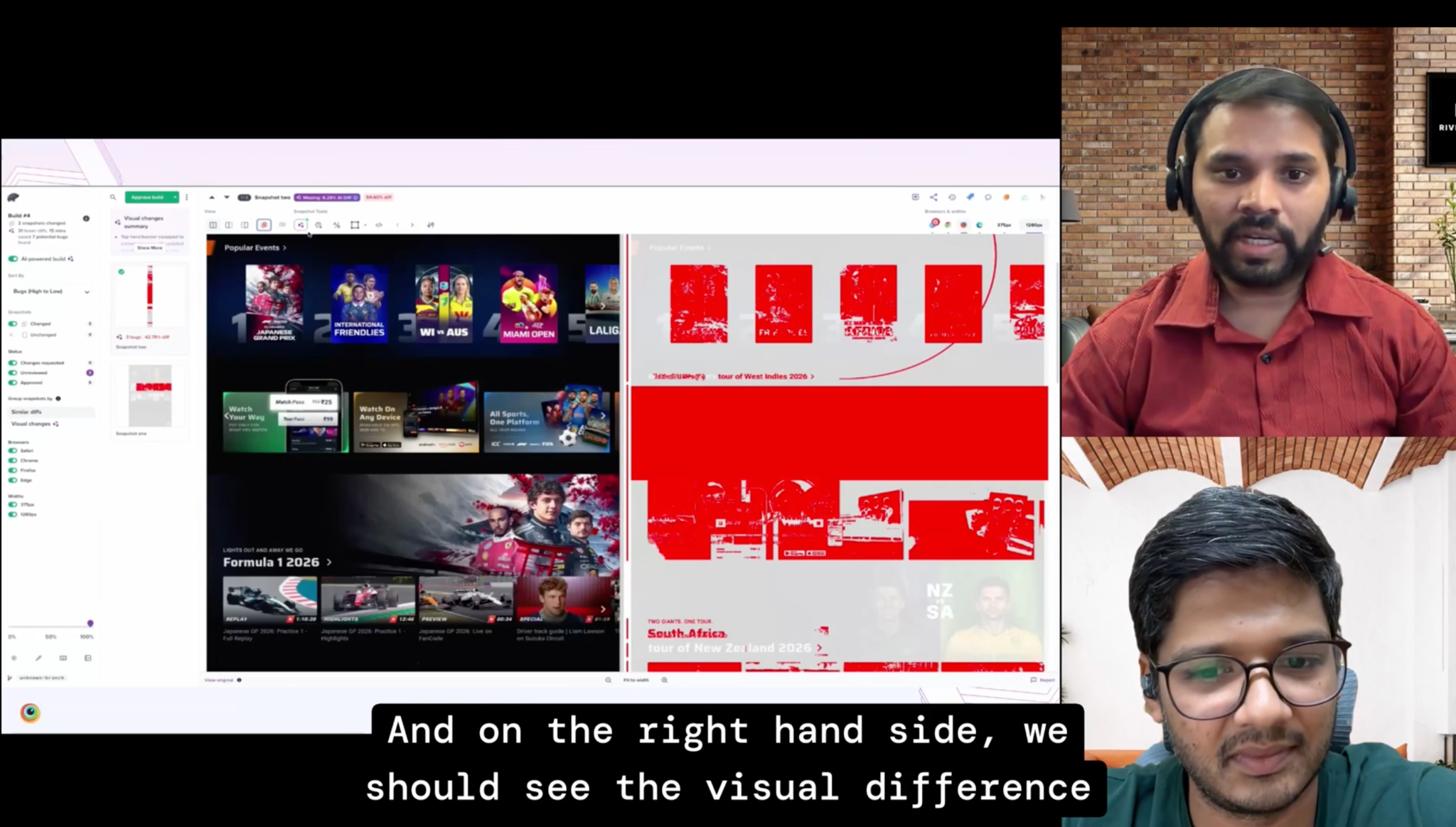
A 0.5px padding error passes every functional test but erodes brand consistency across thousands of pages. Harit Narke showed how Mastercard moved from manual UI reviews to an automated Visual Review Agent in the CI/CD pipeline, cutting a multi-day sign-off process to a 15-minute automated report. Watch it if visual quality at scale is something your team is currently managing manually.
Building Gender-Expansive Teams in Tech

Jenny Bramble, Sophia McKeever, and Jenna Charlton moved well past surface-level DEI language to discuss what actually makes environments safe and inclusive for trans, non-binary, and cis-woman professionals in tech. The panel covered pronoun usage in team settings, holding space in male-dominated sprints, and why psychological safety directly affects the quality of engineering work.
Have Some Cake With Your Frosting: Testing Both the UI and API Layers
Most testing attention drifts toward the UI, but the business logic and the hardest bugs live in the APIs underneath. Hilary Weaver covered why API testing is not just a back-end concern, how HTTP response codes fit into a testing strategy, and how to translate UI test cases into API calls. Watch it if your team is over-indexed on UI coverage and wants a practical path to better test coverage.
What 80% Accuracy Actually Costs: A Production Claude Code and MCP Pipeline
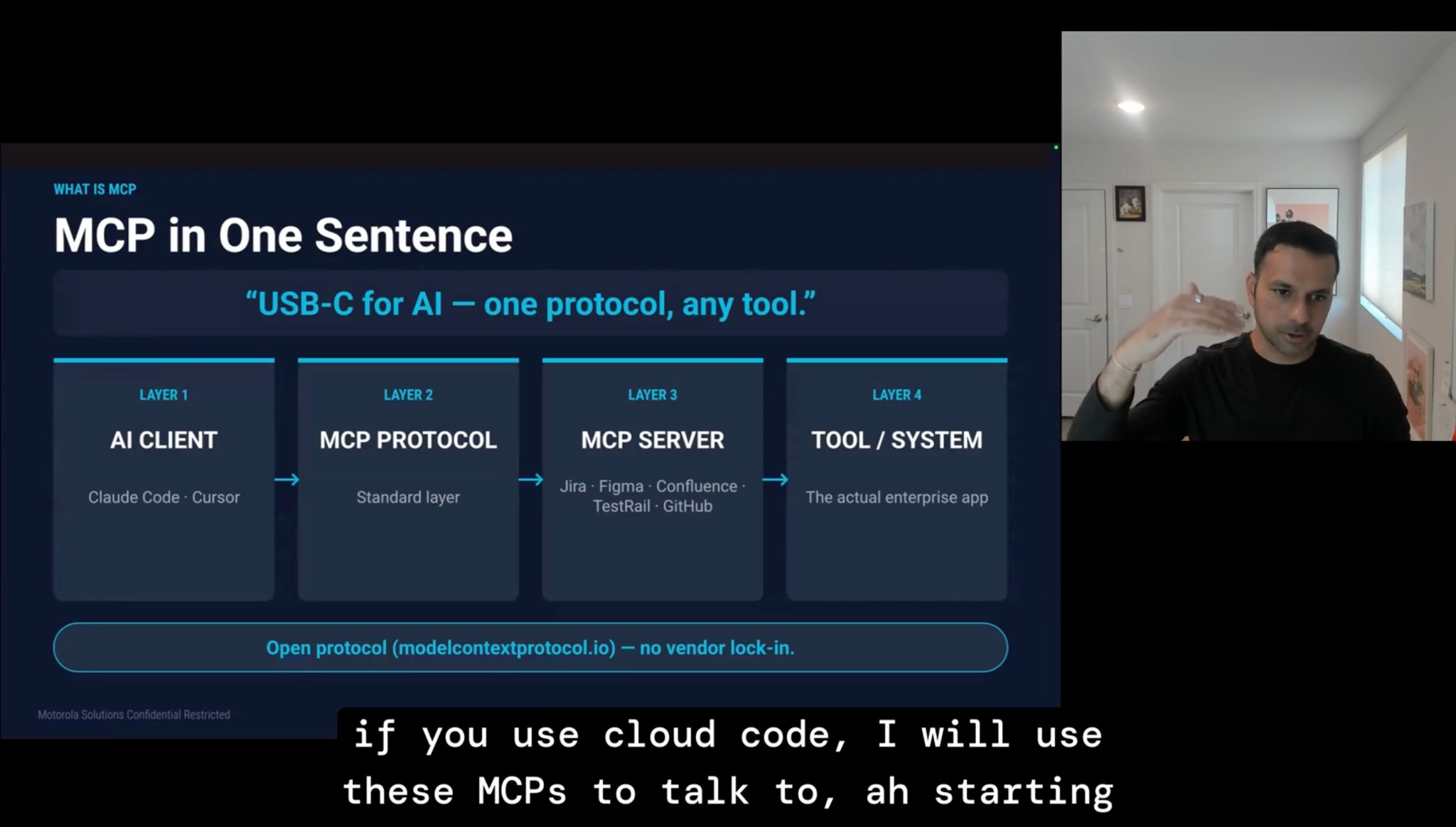
Getting to 80% accuracy with AI code generation tools is achievable. The drag from the remaining 20% is what teams aren't accounting for. Suneet Malhotra walked through a production-grade MCP (Model Context Protocol) pipeline built specifically to close that gap, including how to address AI debt and build guardrails that hold in high-stakes enterprise environments.
Two Major Product Launches: Test Companion and BrowserStack Evals
Breakpoint 2026 was also the stage for two significant BrowserStack product announcements.
- Test Companion is an IDE-embedded AI assistant for generating and debugging test scripts, designed to keep engineers in their workflow rather than context-switching to external tools.
- BrowserStack Evals addresses one of the defining problems of AI-native testing: how do you measure the output of a system that does not produce deterministic results? BrowserStack Evals is built specifically to validate non-deterministic AI outputs at scale, which makes it a genuinely new category of tool rather than an extension of existing frameworks.
All Sessions Are Free to Watch On Demand
Day 1 covered a lot of ground: two product launches, the case against code as IP, a new framework for testing AI agents, and practitioners from Mastercard, NVIDIA, and Microsoft showing what the shift to AI-native quality engineering looks like in production.
Day 2 shifts from vision to proof: enterprise AI testing benchmarked against real security and scale requirements, run live.