Smarter Test Automation, Powered by Agentic AI
Reduce flakiness, cut debugging time, and minimize test maintenance—so your automation stays fast, stable, and reliable.
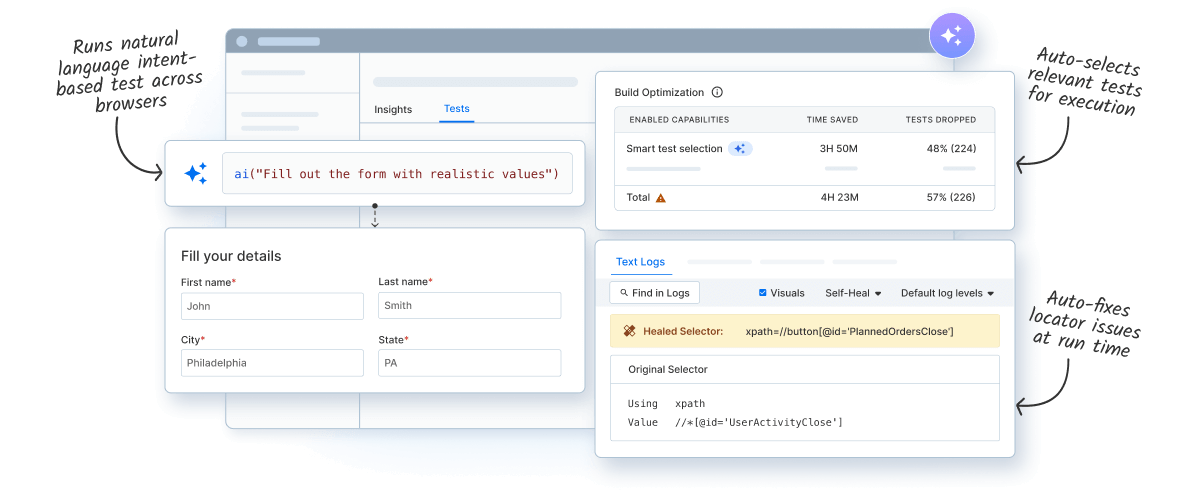
Self-Healing Agent
The Self-Healing Agent detects and remediates broken locators in run time for reduced build failures and suggests resilient locators for permanent fixes.
Reduced maintenance
Automatically remediate locator failures at runtime to reduce maintenance and keep builds green
Reliable AI healing
Use AI to detect DOM and attribute changes with high accuracy and minimal false positives
Broad coverage
Apply self-healing consistently across mobile and web frameworks for reliable test execution
Test Failure Analysis Agent
Synthesises test reports, logs, stack traces, history, similar failures and more to identify failure root cause, type, and suggest actionable next steps for remediation.
Root cause analysis
Synthesizes multiple inputs (test logs, history, smart tags and more) to give an explanation for the test failure
Failure categorisation
Categorizes failure as product bug, environment issue, automation issue or any custom issue based on the RCA
Failure Remediation
Get next steps to remediate the failure or report the bug along with necessary artifacts and fixes
NL Test Automation Agent
The NL Test Automation Agentlets you write tests in natural language instructions, run them across browsers, and reduce script maintenance—so teams ship faster with reliable, cross-platform test coverage.
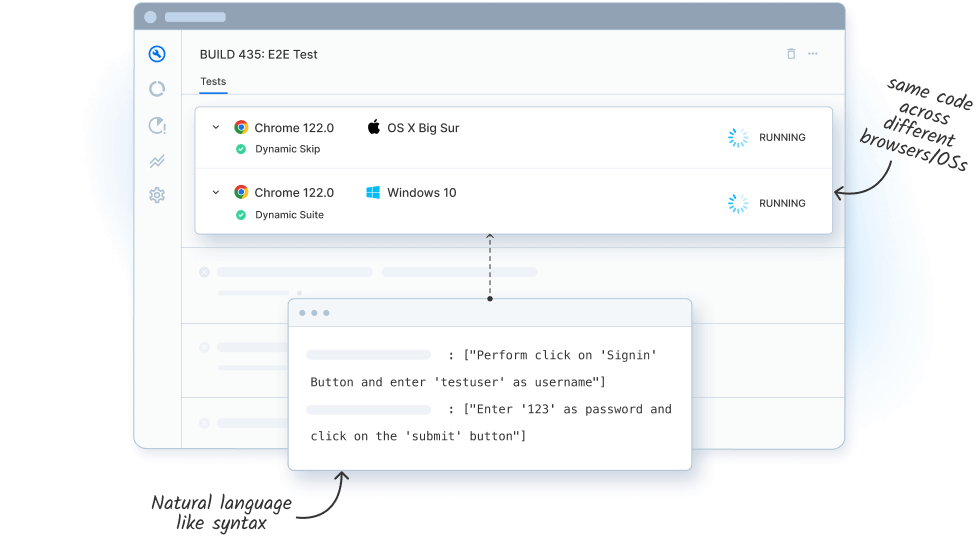
Faster reliable authoring
Write tests in natural language while adaptive navigation ensures stable execution in dynamic environments
Cross-browser portability
Run the same natural language script across browsers, devices, and OS versions with no platform-specific code
Reduced script maintenance
Resolve locator, wait, retry, and UI validation issues automatically with intent-driven execution
Test Selection Agent
Quickly find and run tests most likely to fail based on code changes, reducing build time and infrastructure costs by up to 50%.
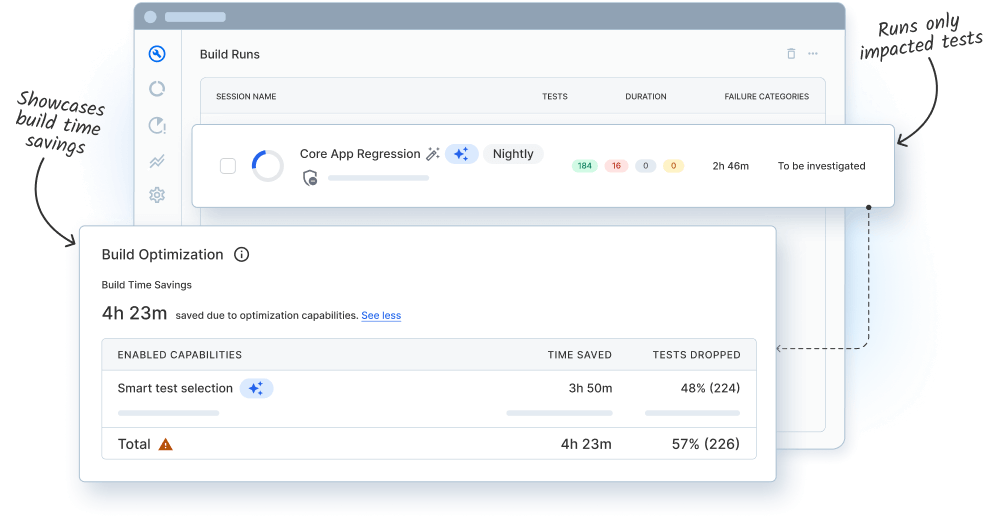
Comprehensive test coverage
Supports unit, API, and end-to-end UI tests across all automation tools, frameworks and environments
Intelligent test execution
Uses test impact analysis to run only impacted tests and safely skip the redundant ones
Easy rollout
Get started instantly with a one-liner CI hook and see speed and efficiency gains from day one
FAQs
Self-healing agent uses AI/ML to detect locator failures and recovers them using baseline snapshots, maintaining test stability without manual intervention.
The self-healing agent captures baseline snapshots and applies AI-powered recovery to fix locators issues, keeping your CI/CD pipeline running.
Yes, healed locators issues are visible in logs and dashboards, showing exactly what was fixed during your test execution.
It converts stack traces and error logs into plain-English explanations using LLM-ready prompts, automatically identifying whether the root cause is in automation code, the product, or the test environment.
Yes — it stitches together logs, traces, hooks, and run history to uncover hidden dependencies, helping teams spot upstream or environment issues that aren’t obvious from a single failure.
Beyond summaries, the agent provides actionable fixes aligned with your framework (e.g., code-level changes or next-step validations), reducing manual trial-and-error in debugging.
Yes, the agent converts the natural language-like syntax into executable test code in real time during test executions.
Seamlessly integrates with Playwright, using act/extract/agent APIs to generate reliable, deterministic test flows from your descriptions.
Creates human-readable tests that blend natural language with code, making them easier to understand and modify by any team member.
Uses AI to analyze failure probability and prioritizes high-risk tests, creating optimized subsets that catch issues faster.
Runs tests most likely to fail first, giving you faster feedback and reducing the time to identify critical issues in your builds.
Analyzes historical data to calculate failure probability for each test, then creates prioritized subsets based on risk and impact.
